企业AI治理新范式:统一调度平台的价值与实践
—— 从分散调用到统一“AI中枢”,让智能资产持续沉淀与演进
一、企业AI应用的现实困境
大模型普及后,企业里的典型场景往往是这样的:
- 客服团队接入 GPT-4
- 内容团队接入 Claude
- 研发团队接入 GLM-4
- 数据团队接入 DeepSeek
每个系统自己管 Key、自己写错误处理、自己做限流和重试;
一旦要切换模型或调整策略,就是一轮“全公司协同 + 改代码”。
这背后至少有几个突出问题:
- 模型碎片化:多套接入方式、多处配置,没有统一视图和治理手段
- 成本不可控:不知道谁用了多少、花在了哪些模型上,更谈不上效果对比和优化
- 缺乏智能调度:简单任务用最贵模型,复杂任务未必拿到最合适资源
- 服务可用性差:单一模型故障可能拖垮一片业务,缺乏自动熔断与备援
- 智能化能力无法沉淀:
- 文档抽取、打标签、事件抽取、向量生成等“小能力”,每个项目都重写一遍
- 高质量 Prompt 散落在代码里,难以在组织内复用
- 自研 AI 组件和模型服务躺在各个项目仓库里,缺少统一纳管和演进机制
企业一边在“全公司上 AI”,一边又在无形中累积技术债和管理债。
二、统一治理:AI能力调度平台的新范式
2.1 什么是 AI 治理与调度平台
AI 治理与调度平台可以理解为企业的“AI 能力总线与中枢”:
- 对上:对所有业务系统暴露统一的 API 入口
- 对下:统一承载多家 LLM、私有大模型、传统 ML 服务和自研业务插件
- 中间:负责智能调度(路由 + 负载均衡 + 熔断降级)、监控与成本治理
一句话总结:
“调用哪个模型 / 哪个服务、以什么策略调用”,不再写死在每个业务里,而是交给平台统一决策。
2.2 架构理念:分层解耦 + 统一调度 + 资产沉淀
用一幅简化架构图来理解平台角色:
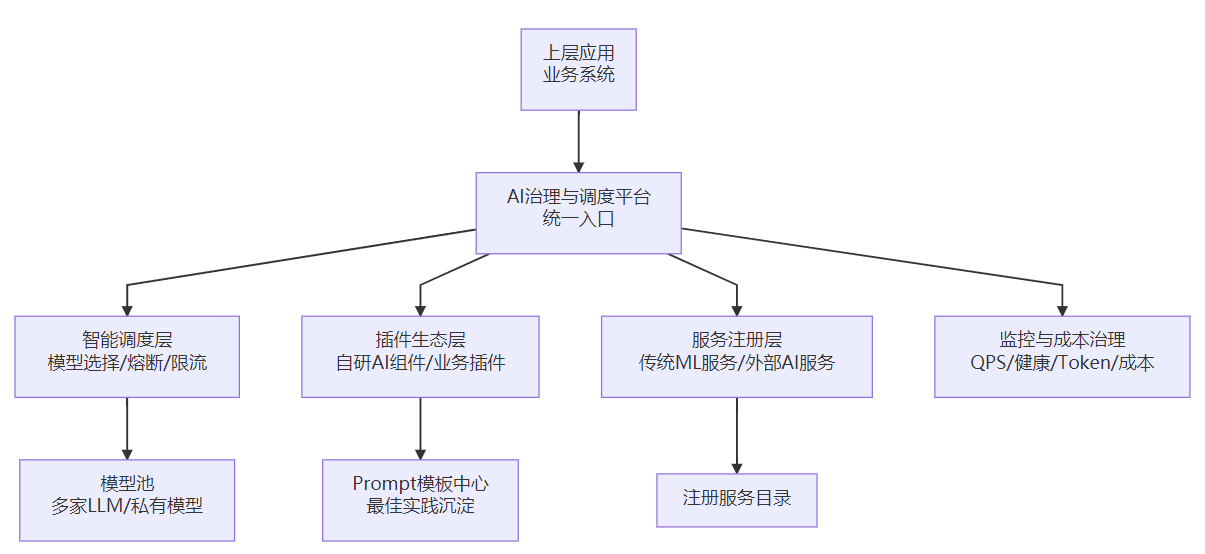
关键设计理念:
- 统一入口:业务只对接平台一个出口,不再“人手一个第三方 API”
- 智能调度:结合业务等级、成本偏好、健康状态、负载等多维因素自动路由
- 插件生态:自研 AI 能力以插件方式接入,做到“可插拔、可复用、可统一调度”
- 服务注册:传统 ML / 外部 AI 服务通过注册机制纳管,统一做健康检查和调度
- 监控与成本治理:平台统一采集 QPS、延迟、错误率、Token 与成本数据
- 智能资产沉淀:Prompt 模板、自研组件、行业最佳实践,在平台中持续沉淀和演进
三、核心价值:解决企业AI治理的四大痛点
3.1 模型碎片化 → 统一管理与调度
问题本质:模型接入点太多、配置分散,难以统一治理,也难以灵活切换。
平台将所有模型集中到一个模型池里:
- 模型配置统一管理,可动态增删改
- 业务只依赖“平台接口”,而不是具体模型厂商 API
- 模型升级、切换、灰度发布都可以在平台层完成
带来的变化:
- 管理、排障、审计都有了全局视角
- 从“改 N 个系统代码”变成“调一处平台配置”
- 为未来接入新模型、私有部署等预留了充分空间
3.2 成本不可控 → 精准统计 + 策略化调度
平台对每次调用的Token 与成本做精细记录,支持按:
- 模型
- 用户 / 租户
- 业务线 / 应用
等维度进行聚合分析,并提供:
- 成本偏好参数(例如:
prefer_cost = "low/high") - 业务等级参数(例如:
biz_level = "premium/normal/economy")
借此在调度时综合考虑“效果 / 成本 / 延迟”的平衡。
结果:
- “AI 花了多少钱、花在了哪儿”可以说清楚
- 哪些模型“贵但不值”、哪些模型“便宜好用”,有数据支撑
- 高价值业务可以用更好的模型,低价值大量任务可调度到低成本模型上,整体 ROI 可控可算
3.3 缺乏智能路由 → 多维度智能调度
业务不再自己判断“该用哪个模型”,而是只需声明:
- 业务等级:
premium / normal / economy - 成本偏好:更看重价格还是效果
- 能力标签:多语言、代码、长上下文等
平台层综合考虑:
- 模型健康状态(healthy / unknown / 下线)
- 当前并发与 QPS 压力
- 历史错误率与延迟表现
- 成本与预算约束
自动完成“选模型、分流量、做降级”的智能调度决策。
结果:
- 资源利用率更高,不再“简单任务用豪车”
- 用户体验更稳,单点故障不再“牵一发动全身”
- 调度策略可以随时间和数据持续优化,而不用反复改业务代码
3.4 扩展性差 → 插件化生态 + 统一调度
新的 AI 能力(比如合同要点提取、政策条款结构化、行业新闻摘要):
- 不再写死在各业务系统里
- 而是作为插件在平台侧开发与注册
- 对上暴露统一接口,可以被多个系统共享调用
- 对下可以统一通过平台调度 LLM、传统 ML 或外部服务
好处:
- 一次开发,多处复用,减少重复造轮子
- 插件可以独立演进(换模型、改 Prompt、调参数),调用方无感知
- 配合 Prompt 模板中心,可以形成“行业能力包”,快速复制给不同客户或业务线
四、智能资产:持续沉淀与演进的组织能力
真正拉开企业差距的,不是“谁先接上了哪个大模型”,而是:
谁能把自己做出来的 AI 能力和经验,变成可复用、可调度、可演进的智能资产。
4.1 Prompt 模板中心:从代码里“挖出来”的组织记忆
平台将关键 Prompt 从业务代码中抽离,集中管理:
- 按业务场景 / 行业 / 插件分类组织
- 支持版本管理、在线编辑、热更新
- 能绑定到具体插件和能力上,用于统一调度
价值:
- 新项目不再从 0 设计 Prompt,而是从“成熟模板 + 小改动”开始
- 模板一旦优化,所有使用它的插件和业务一起受益
- Prompt 变成可见、可管、可迭代的“文本代码资产”,而不是散落在 Chat 记录和本地脚本里的“隐形财富”
4.2 自研 AI 组件及模型服务的统一纳管与调度
在很多公司,自研 AI 组件和模型服务散落在:
- 某个项目里的
doc_extractor.py - 某个团队维护的私有服务接口
- 若干封装在业务代码里的“小逻辑”
在 AI 治理与调度平台中:
- 这些组件通过插件机制暴露为统一的 API 能力,可以被调度和编排
- 传统 ML / 外部 AI 服务通过服务注册纳入平台,由平台统一转发和监控
- 平台在调度时,可以同时考虑 LLM、自研组件和传统 ML 的优劣与成本
于是:
- 一系列自研 AI 组件及模型服务,不再只是“某个项目的代码”,而是企业级“能力积木”
- 后续对这些能力的优化(模型升级、Prompt 微调、策略调整),可以直接“反哺”所有调用它们的业务
- 新项目可以站在过去所有项目积累之上,而不是重走相同的坑
4.3 从项目导向到资产导向:长期复利的起点
传统模式下:
- 项目交付完成,代码进仓库,后续很少系统性复用
- 很多宝贵经验停留在个人或小团队头脑中
平台模式下:
- 每个项目在解决业务问题的同时,也在给平台贡献:
- 新插件
- 新 Prompt 模板
- 新的组合与实践经验
- 下一批项目天然以这些资产为起点,组织整体 AI 能力随时间“滚雪球”
这就是所谓的:
有了这样一个 AI 治理与调度平台,才能让一系列自研 AI 组件及模型服务真正实现持续沉淀与演进。
五、应用场景:谁最适合用这样的平台
中大型企业
- 多条业务线在用 AI,希望有统一入口和统一调度能力
- 计划建设 AI 中台 / 能力中枢,避免重复建设
- 希望历史项目沉淀出的自研能力,成为长期资产,而不是一次性成本
软件公司 / ISV
- 需要频繁为不同行业客户交付“定制化 AI 能力”
- 希望把共性的 AI 能力抽象、产品化,形成模块化能力库
- 希望形成自己的“AI 能力资产池”,而不是一堆散落的项目仓库
AI 能力开放平台提供方
- 需要对外提供统一、稳定、可计费的 AI API
- 需要能力发现、计费分账、多租户治理等平台级能力
规划 AI 中台 / 数据中台的企业
- 希望在数据中台之上,搭建一个可持续演进的“智能层”
- 需要统一管理 LLM、传统 ML、规则引擎、知识图谱等多源智能能力,并进行统一调度
对这些组织而言,这样的平台带来的,并不仅是“几个项目开发快一点”,而是:
之后所有 AI 项目都能站在同一个、不断抬升的能力底座上。
六、结语:从“用模型”到“经营智能资产”
统一的 AI 治理与调度平台,在三个层面为企业带来升级:
-
工程层面:
从分散对接到统一入口,从硬编码模型到策略化、智能化调度。 -
管理层面:
从粗放使用到可度量、可治理、可优化,成本和效果都可以被量化和调优。 -
组织层面:
从“做一个项目解决一个问题”,到“每个项目都为企业 AI 资产池添砖加瓦”,
让自研 AI 组件及模型服务真正成为可持续复用与演进的智能资产。
大模型让“智能能力”变得触手可及,而一个好的 AI 治理与调度平台,则让这些智能留得住、用得好、越用越强。
对于希望在 AI 时代形成长期竞争力的企业来说,这一步,值得尽早迈出。