A New Paradigm for Enterprise AI Governance: The Value and Practice of a Unified Scheduling Platform
— From scattered model calls to a unified “AI hub”, turning intelligent capabilities into evolving assets
I. Real-World Challenges of Enterprise AI Adoption
With large language models going mainstream, a common pattern inside enterprises is:
- Customer support uses GPT‑4
- Content teams use Claude
- Engineering uses GLM‑4
- Data teams use DeepSeek
Each system manages its own keys, error handling, rate limiting and cost control.
Once you need to switch models or adjust strategies, it quickly becomes a company-wide “coordination + code change” campaign.
This leads to several issues:
- Model fragmentation: Integrations are scattered, with no global view or unified governance
- Uncontrolled cost: Hard to know who spent how much on which models, and what the ROI is
- No intelligent scheduling: Simple tasks use the most expensive model, while complex tasks may not get optimal resources
- Poor availability: A single model outage can impact many systems if there is no automatic fallback
- No accumulation of “intelligent assets”:
- Document extraction, tagging, event extraction, embeddings, etc. are re‑implemented in each project
- High‑quality prompts stay hidden in code or notebooks
- In‑house AI components and model services remain project‑specific and hard to reuse or evolve
II. A New Paradigm: AI Governance and Scheduling Platform
2.1 What Is an AI Governance and Scheduling Platform?
An AI governance and scheduling platform acts as the enterprise’s AI bus and hub:
- Upstream: exposes a single, stable API entry point to all business systems
- Downstream: manages multiple LLM vendors, private models, traditional ML services and in‑house plugins
- In the middle: performs intelligent scheduling (routing, load balancing, fallback), plus monitoring and cost governance
In other words:
“Which model/service to call, and under what strategy” is no longer hard‑coded in each app,
but decided centrally by the platform.
2.2 Architectural View: Layers and Responsibilities
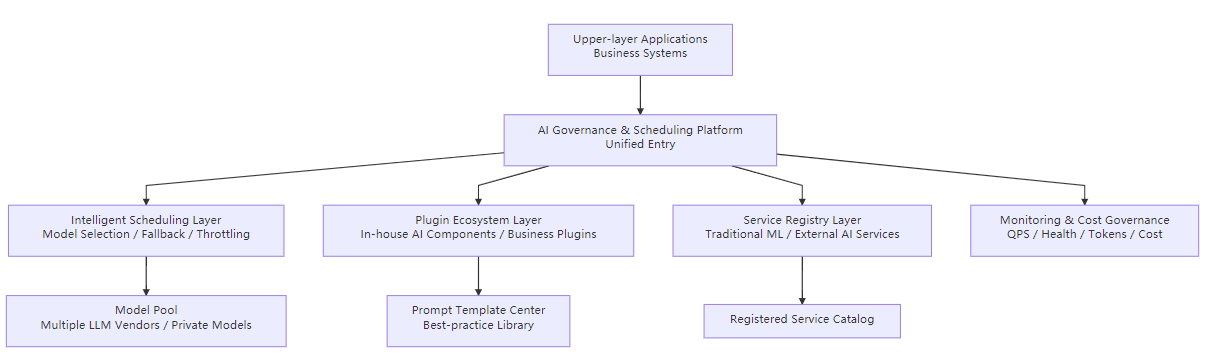
Key ideas:
- Unified entry: business systems integrate once, use many models/services behind the scenes
- Intelligent scheduling: the platform decides routing based on business tier, cost preference, health and load
- Plugin ecosystem: in‑house AI capabilities are exposed as plugins, reusable and centrally scheduled
- Service registry: traditional ML and external AI services are registered and governed centrally
- Monitoring & cost governance: QPS, latency, error rates, tokens and cost are tracked at platform level
- Intelligent asset accumulation: prompts, plugins and best practices become shared, evolving assets
III. Core Value: Solving Four Major Pain Points
3.1 From Model Fragmentation → Unified Management and Scheduling
A centralized model pool:
- Holds all model configurations in one place
- Decouples business logic from specific vendors
- Allows upgrades, switching and A/B testing at the platform level
This significantly reduces integration and coordination overhead, and keeps the door open for new models and deployments.
3.2 From Uncontrolled Cost → Precise Accounting + Policy-Driven Scheduling
The platform:
- Logs tokens and cost for every call
- Aggregates by model, tenant, business line, and application
- Allows each business to specify cost vs. quality preferences and business tiers
Scheduling decisions then balance quality, latency and cost automatically.
Outcome:
- You know who spent how much on which models
- You can see which models are “expensive but underperforming”
- High‑value traffic can be steered to stronger models, while low‑value or bulk workloads go to cheaper ones
3.3 From Ad-Hoc Routing → Multi-Dimensional Intelligent Scheduling
Instead of hard‑coding model choices, business systems simply declare:
- Business tier:
premium / normal / economy - Cost preference: cost‑first vs. quality‑first
- Capability tags: multilingual, coding, long‑context, etc.
The platform combines this with:
- Model health and availability
- Current load (QPS, concurrency)
- Historical latency and error rates
- Budget and cost constraints
to perform end‑to‑end intelligent scheduling: routing, load balancing, fallback and degradation.
3.4 From Poor Extensibility → Plugin-Based Ecosystem + Unified Scheduling
New AI capabilities (contract key‑point extraction, policy parsing, industry news summarization, etc.):
- Are implemented as platform plugins, not buried inside each app
- Exposed through unified APIs, reusable across systems
- Centrally scheduled: a plugin can internally use LLMs, traditional ML or external services, all coordinated by the platform
This enables “build once, reuse everywhere”, faster rollout of new capabilities and lower maintenance cost.
IV. Intelligent Assets: Organization-Level Capabilities
The real long‑term differentiator is not who connects to which model first, but:
Who can turn their AI components, prompts and best practices
into continuously evolving intelligent assets.
4.1 Prompt Template Center
- Extracts critical prompts from scattered code and centralizes them in a prompt library
- Organizes by scenario / industry / plugin
- Supports versioning, online editing and hot reload
New projects can start from proven templates; improvements to a template benefit all consumers at once.
4.2 Unified Management and Scheduling of In-House AI Components
In many organizations, in‑house AI components and model services live in:
- Individual project repositories
- Team‑owned private services
- Small logic blocks inside business code
The platform promotes them to first‑class capabilities:
- Registered as plugins or services with clear contracts
- Scheduled together with LLMs and traditional ML
- Evolved centrally (better prompts, better models, better policies) without changing callers
Every project thus contributes new “building blocks” to the enterprise AI asset pool.
4.3 From Project-Centric to Asset-Centric
Previously:
- Each project implemented its own extraction, tagging, summarization logic
- Code and know‑how stayed within that project team
With an AI governance and scheduling platform:
- Each project leaves behind plugins, prompt templates and best practices
- Future projects can assemble solutions from these assets instead of reinventing them
- The organization’s AI maturity compounds over time
This is what it means to turn a series of self-developed AI components and model services into long-term intelligent assets.
V. Who Benefits the Most
- Mid‑to‑large enterprises: multiple business lines using AI, needing a unified AI hub and scheduling layer
- Software vendors / ISVs: turning scattered project code into productized, reusable AI capabilities
- AI API / platform providers: needing unified external APIs, service discovery, billing and ecosystem support
- Organizations building AI middle platforms: wanting a sustainable intelligent layer above data and services
For all of them, the key benefit is that every new AI project starts higher than the last one,
because the platform keeps accumulating and evolving intelligent assets in the background.
VI. Conclusion: From “Using Models” to “Operating Intelligent Assets”
A unified AI governance and scheduling platform upgrades the enterprise on three levels:
- Engineering: from scattered integrations to a unified, intelligent entry point
- Management: from opaque spending to measurable, optimizable AI usage
- Organization: from project‑by‑project output to an ever‑growing pool of reusable AI capabilities
LLMs make “intelligence” accessible;
an AI governance and scheduling platform makes that intelligence stick, improve and compound over time.
For enterprises seeking sustainable advantage in the AI era, this is a step worth taking early.
Author: Zhengzhou Shuneng Software Technology Co., Ltd.
Tags: ai-platform · ai-governance · ai-scheduling · llm-gateway · enterprise-ai · intelligent-assets
|
|